We are happy to announce the release of TextPAIR, a new sequence aligner focused on detecting reuses in large body of texts. In many ways, TextPAIR is a successor to the old TextPAIR and PhiloLine released in 2009. But it also differs in important ways which we will highlight here.
The ARTFL-Project has long worked on intertextuality (see our papers section on the ARTFL site), and finding ways to detect similar passages in running text. Although we found great success with PhiloLine, particularly in the context of the Commonplace Cultures project, we also faced certain limitations which we wanted to address, particularly in the case of our recent project to explore the legacies of the Enlightenment in 19th century print culture.
As a result, when we started designing the new generation of our sequence aligner, we decided to focus on performance. We also wanted to leverage the rich Python ecosystem of NLP tools, so we decided that we would write this new package in Python (PhiloLine was written in Perl). After a redesign of the matching algorithm, the initial Python version was able to run about 1.5 to 2 times faster, but with also a much higher RAM usage, about 4-6 times more than PhiloLine. Certainly not a ground-breaking difference... Accelerating the alignment by parallelizing the task was out of the question given the memory cost of using multiprocessing in Python.
While we could have at that point decided to use Cython to gain C speed and parallelize the code, we decided to take a look at Go, a relatively new language developed at Google, which excels at running concurrent tasks, and runs significantly faster than Python. After a proof of concept rewrite in Go showed that we could run an alignment of all ARTFL-Frantext's 3,500 texts in under 4 hours on a single core, a task that took about 10 hours with the Python version,, we decided to go for a pure Go implementation of the core aligner code. While the RAM usage was a bit lower in Go than in Python, it was still somewhat high for our purposes, so we decided to use only 32 bit integers for all integer values (instead of the 64 bit default), effectively halving our memory usage. Our highest potential integer values are in the byte positions of passages within documents, and given that we are unlikely to find a 2,147,483,647 -- the maximum value for 32 bit signed integers -- byte text file anytime soon, there was no risk in switching to 32 bit integers.
After a number of optimizations to the code, we were able to bring down the runtime of our ARTFL-Frantext alignment to a mere 11 minutes (!!!), leveraging all 16 cores (and 32 threads) of our server. With the Python preprocessing included (which combines various normalization steps and the ngram creation), as well as the database loading and web application building, it took a total of 20 minutes to go from the PhiloLogic parsed output to a full functioning web application capable of search through the 60,000 alignments. As a result of these optimizations, we were able to compete the alignment of our Enlightenment legacies project, which compared 1,300 texts from before the 19th century to 115,000 files from the TGB collection, in about 4 hours, most of which was spent preprocessing and filtering the OCR files from the TGB. We were able to run this alignment multiple times using different parameters in order to obtain the best set of results.
We have also worked on building a virtual modernization pipeline for both English (relying on Martin's Mueller's work on TCP resources) and French (using the work Marine Riguet did on modernizing old forms in ARTFL-Frantext). This is an important feature to have when comparing texts from different periods. The typical example in French would be converting old forms of the imperfect ending in -ois/-oit/-oient to -ais/-ait/-aient.
As we were working on this code, we realized it would be more useful to break-up this preprocessing step from the TextPAIR code so we could reuse it for other text analysis work. We've therefore created a separate library, called text-preprocessing, which is available on Github, and which we are constantly working to improve separately from the TextPAIR code.
Read More
The ARTFL-Project has long worked on intertextuality (see our papers section on the ARTFL site), and finding ways to detect similar passages in running text. Although we found great success with PhiloLine, particularly in the context of the Commonplace Cultures project, we also faced certain limitations which we wanted to address, particularly in the case of our recent project to explore the legacies of the Enlightenment in 19th century print culture.
Higher performance
The first issue that we wanted to address was that of performance. PhiloLine certainly wasn't slow, but it also wasn't designed to run a very large scale datasets, and remains to this day an experimental implementation meant to be replaced by a more optimized version. It served us well during the Commonplace Cultures project, where we ran the aligner against 200,000 texts. But the task also took 3 weeks to run, and needed to be broken up into several batches to run entirely. The results were certainly fruitful (over 40 million shared passages were detected!), but rerunning the task with a different set of parameters was out of the question given the deadline for the completion of the project.As a result, when we started designing the new generation of our sequence aligner, we decided to focus on performance. We also wanted to leverage the rich Python ecosystem of NLP tools, so we decided that we would write this new package in Python (PhiloLine was written in Perl). After a redesign of the matching algorithm, the initial Python version was able to run about 1.5 to 2 times faster, but with also a much higher RAM usage, about 4-6 times more than PhiloLine. Certainly not a ground-breaking difference... Accelerating the alignment by parallelizing the task was out of the question given the memory cost of using multiprocessing in Python.
While we could have at that point decided to use Cython to gain C speed and parallelize the code, we decided to take a look at Go, a relatively new language developed at Google, which excels at running concurrent tasks, and runs significantly faster than Python. After a proof of concept rewrite in Go showed that we could run an alignment of all ARTFL-Frantext's 3,500 texts in under 4 hours on a single core, a task that took about 10 hours with the Python version,, we decided to go for a pure Go implementation of the core aligner code. While the RAM usage was a bit lower in Go than in Python, it was still somewhat high for our purposes, so we decided to use only 32 bit integers for all integer values (instead of the 64 bit default), effectively halving our memory usage. Our highest potential integer values are in the byte positions of passages within documents, and given that we are unlikely to find a 2,147,483,647 -- the maximum value for 32 bit signed integers -- byte text file anytime soon, there was no risk in switching to 32 bit integers.
After a number of optimizations to the code, we were able to bring down the runtime of our ARTFL-Frantext alignment to a mere 11 minutes (!!!), leveraging all 16 cores (and 32 threads) of our server. With the Python preprocessing included (which combines various normalization steps and the ngram creation), as well as the database loading and web application building, it took a total of 20 minutes to go from the PhiloLogic parsed output to a full functioning web application capable of search through the 60,000 alignments. As a result of these optimizations, we were able to compete the alignment of our Enlightenment legacies project, which compared 1,300 texts from before the 19th century to 115,000 files from the TGB collection, in about 4 hours, most of which was spent preprocessing and filtering the OCR files from the TGB. We were able to run this alignment multiple times using different parameters in order to obtain the best set of results.
A revamped preprocessing stage
A big aspect of the aligner rewrite was our decision to rely as much as possible on the fledging Python ecosystem for all of our text preprocessing. There are many libraries available for preprocessing, but we decided to leverage Spacy, a well-documented and ever improving NLP library, for part-of-speech tagging and lemmatization. We do plan on using more of its features in the future.We have also worked on building a virtual modernization pipeline for both English (relying on Martin's Mueller's work on TCP resources) and French (using the work Marine Riguet did on modernizing old forms in ARTFL-Frantext). This is an important feature to have when comparing texts from different periods. The typical example in French would be converting old forms of the imperfect ending in -ois/-oit/-oient to -ais/-ait/-aient.
As we were working on this code, we realized it would be more useful to break-up this preprocessing step from the TextPAIR code so we could reuse it for other text analysis work. We've therefore created a separate library, called text-preprocessing, which is available on Github, and which we are constantly working to improve separately from the TextPAIR code.
A much improved Web Application
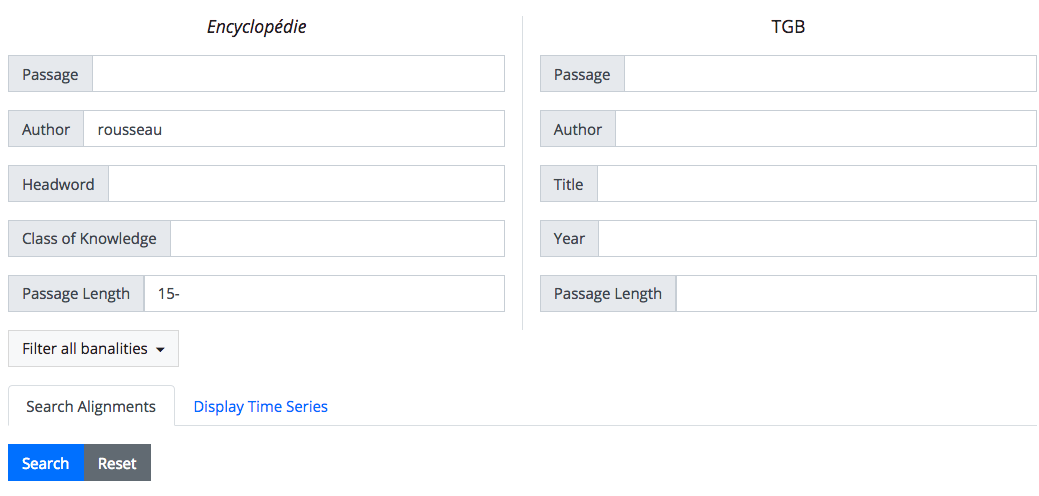
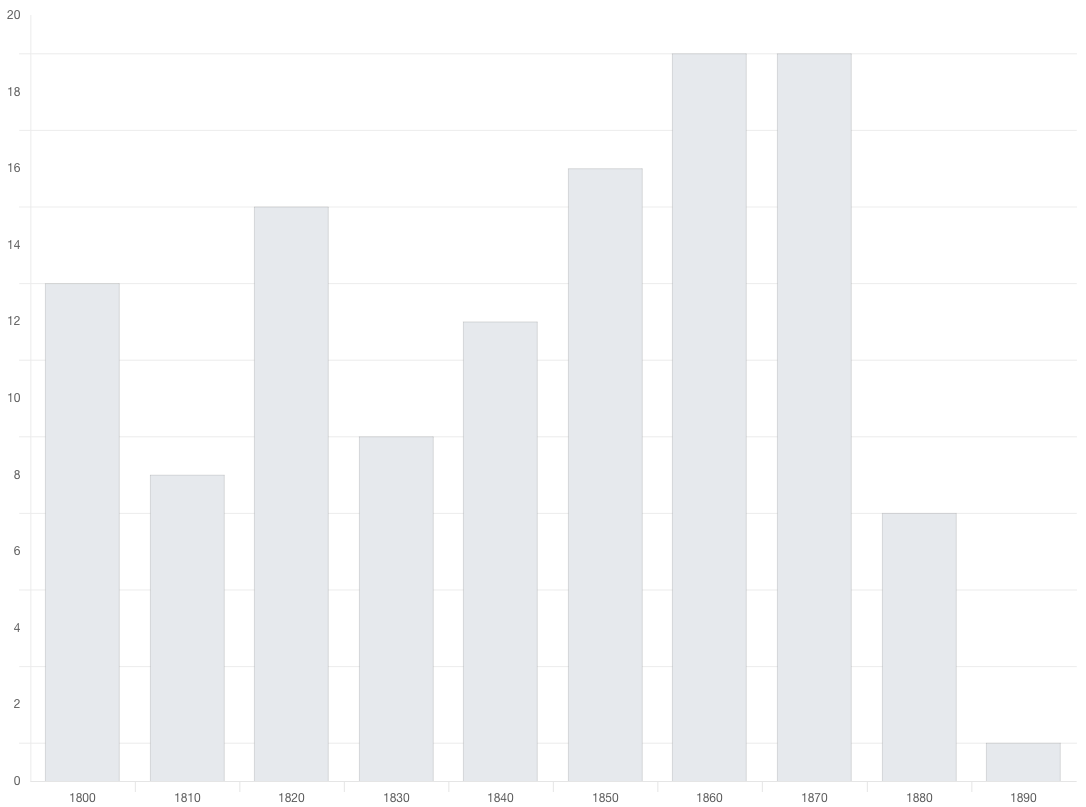
The original PhiloLine had a web application associated with it, and which could be used to search through alignments. But the feature set was restricted to searching shared passages using various metadata filtering options. Following in PhiloLogic4's footsteps, TextPAIR's Web interface has added faceted browsing to aggregate reuses in a way that gives a better overall perspective on the reuses present in the database. We also offer a Time Series view of shared passages to better understand how any given author/work has been reused accross time. And finally, we've worked on getting it integrated into PhiloLogic4 (when alignments were built from PhiloLogic4 output) by providing contextual links that take you straight to a PhiloLogic instance.Future work
We are looking to improve the current version of TextPAIR on different fronts:- Provide an alternate matching algorithm that can link together more loosely related passages
- Allow for easier configuration of various components of the aligner and Web Application
- Include a contextualization feature within TextPAIR (as an alternative to linking to a PhiloLogic instance)
- Provide visualizations of alignments showing clusters of reuses, as well as of document to document shared passages
Some examples of currently running alignment databases
- Practices and Legacy of 18th Century Culture
- Frantext and the the French Revolutionary Collection
- Reuses in ARFL-Frantext
- Reuses in ARTFL-Frantext and the ARTFL-Encyclopédie
TextPAIR is fully open-source, and we gladly welcome any comments and/or contributions.