ARTFL is proud to announce the release of two large-scale sequence alignment databases built within the context of a collaborative project with l'Observatoire de la Vie Littéraire (OBVIL). The goal of this project was to investigate the legacy of the French Enlightenment on 19th century print culture. Thanks to the release by the BNF of the "Très Grand Bibliothèque" (TGB), a collection of 128,000 texts from their digital archive, we attempted to evaluate the presence of Enlightenment discourse within the French 19th century, relying on well-known text-reuse detection techniques. This project represented a natural outgrowth from previous research into sequence alignment in large collections, and resulted in the open-source release of TextPAIR, a high performance sequence aligner capable of comparing hundreds of thousands of documents in a mere 4 or 5 hours.
We used two well-curated datasets from the ARTFL Project holdings to form the test samples to identify Enlightenment discourse. The first are the 1,367 documents that comprise the pre-19th century holdings in ARTFL Frantext. This dataset contains a significant, though by no means complete, sample of major and minor French Enlightenment published works. We decide to retain Frantext’s 17th century holdings as part of this study. Thus, the most frequent authors with more than 10 works in this collection are shown in Table One (see bottom of post). The second sample is the complete text of the Encyclopédie of Diderot and d’Alembert as found in the ARTFL edition of this famous work. As mentioned, the ARTFL Frantext corpus and the Encyclopédie are both curated collections that have been largely corrected of input and other errors as well as being reasonable close transcriptions of the original documents with most later editorial interventions having been removed.
The TGB collection, which was meant to be a representative sample of French 19th century print culture, is comprised 128,441 documents which were digitized using Optical Character Recognition. As expected, the quality of the raw data varies widely depending on a whole range of factors, including age, preservation status and print quality, though it was overall of good quality. On the other hand, the document-level metadata was quite inconsistent, and sometimes incorrect, so our collaborators at the Observatoire de la Vie Littéraire had to perform some extensive preliminary work in order to get the data ready for our alignment experiments. This included a number of authorship attribution issues, as well as normalizing the spelling of each author found in the corpus. Additionally, while the vast majority of the texts in the TGB were published during the 19th century, the collection has a significant number of documents which were originally published before 1800. Most of these documents were reprints of earlier texts in complete or selected works or, less commonly, as individual reprints. We used a series of heuristics based on the metadata provided by the BNF to eliminate duplicates and texts originally published before 1800. We removed 17,063 documents from the TGB sample, with the top authors removed listed in Table Two (see bottom of post). This left 112,907 documents in the TGB sample. There are, of course, some titles that should have been retained in the sample and others that should have been removed, since the criteria for removal was based on fairly simple heuristics, such as removing most titles identified as complete works and looking at author year of birth or death, where available, as another criteria. Given that our goal was to draw a picture of the legacy of the Enlightenment using a representative sample of works published in the 19th century, this was a well worth tradeoff given the potential for many false positive reuses that would have been detected from leaving in texts originally written in previous centuries.
Since the primary task of this project is the identification of reused passages, we used the combined word lists of the Frantext sample and the Encyclopédie as the list of words to index in the TGB for both search and alignment applications. This was done in order to reduce the number of unique words (types) to a manageable level and to ignore all the potential OCR errors using the well attested word list of work from our well-curated texts. It did not have an impact on the alignment tasks since we use exact n-gram matching, so any words not found in the source text word list would not be found in the target text. We retained 193,908 types, amounting to a total of 2.1 billion words (tokens).
On the other hand, the articles that are most often cited in today’s discussions of the Encyclopédie, those heavily ideological articles laying out the aims and goals, those that make us see the Encyclopédie as an engin de guerre for the philosophes, are cited less often than we expected. Thus an author like d’Holbach is rarely reprised in the context of his specifically materialistic articles and more for articles he wrote on mineralogy and chemistry. All of this is to say, that Encyclopédie did have a significant impact in the 19th century, but it was not that which we had expected.
This work is just beginning and we will soon begin to look more closely at the bigger picture – not just the Encyclopédie in the TGB, but all of our various 18th century holdings (including the 18th century texts contained in the TGB corpus itself) – to broaden our understanding of reuse of 18th century in the post-Revolutionary era of the 19th century.
Direct Outcomes of this project
This project resulted in a number of related deliverables. Most importantly is the open source distribution of TextPAIR, as this provides a new model for handling very large scale alignment tasks.
https://github.com/ARTFL-Project/text-pair
The importance of this new software is underlined by the ARTFL Project release of a build of the Newberry French Revolution Collection which includes a open release of an alignment database of ARTFL pre-Revolutionary collection and the more than 26,000 Revolutionary documents. This allows scholar to look directly at the long standing question of the relationship between the Enlightenment and the Revolution.
The second and equally important deliverable from this collaborative work is the publication at ARTFL of both alignment databases as described above. These are complete installations of the alignment databases except that we have disabled links to the full texts of underlying datasets owing to agreements with various collaborators.
Home page of our alignment databases: http://artfl-project.uchicago.edu/legacy_eighteenth
ARTFL Encyclopédie to TGB alignment database: https://artflsrv03.uchicago.edu/text-align/encyc_vs_TGB_0803/
The ARTFL-Frantext to TGB alignment database: https://artflsrv03.uchicago.edu/text-align/frantext_vs_TGB_0803/
TABLE One: Frequency of authors (shown with dates) in the Frantext Sample
Voltaire, 1694-1778. 85
Diderot, Denis, 1713-1784. 45
Corneille, Pierre, 1606-1684. 37
Molière, 1622-1673. 34
Aulnoy, Madame d'(Marie-Catherine), 1650 or 51-1705. 31
Fontenelle, M. de (Bernard Le Bovier), 1657-1757. 23
Marivaux, Pierre Carlet de Chamblain de, 1688-1763. 22
Bossuet, Jacques Bénigne, 1627-1704. 21
Saint-Simon, Louis de Rouvroy, duc de, 1675-1755 20
Rousseau, Jean-Jacques, 1712-1778. 17
Mersenne, Marin, 1588-1648. 16
Charrière, Isabelle de, 1740-1805. 14
Fénelon, François de Salignac de La Mothe-, 1651-1715. 13
Montesquieu, Charles de Secondat, baron de, 1689-1755. 13
Prévost, abbé, 1697-1763. 13
Racine, Jean, 1639-1699. 13
La Fontaine, Jean de, 1621-1695. 11
Marot, Clément 11
Balzac, Jean-Louis Guez, seigneur de, 1597-1654. 10
Du Bellay, Joachim 10
Scudéry, M. de (Georges), 1601-1667. 10
Table Two: Top Authors removed from TGB
Voltaire (1694-1778) 249
Molière (1622-1673) 243
Racine, Jean (1639-1699) 139
Corneille, Pierre (1606-1684) 132
La Fontaine, Jean de (1621-1695) 129
Chateaubriand, François-René de (1768-1848) 112
Scott, Walter (1771-1832) 105
Boileau, Nicolas (1636-1711) 100
Fénelon, François de (1651-1715) 96
Scribe, Eugène (1791-1861) 84
Rousseau, Jean-Jacques (1712-1778) 72
Rollin, Charles (1661-1741) 69
Diderot, Denis (1713-1784) 64
Louis (1755-1824) 63
Florian, Jean-Pierre Claris de (1755-1794) 60
Marmontel, Jean-François (1723-1799) 58
Prévost, Antoine François (1697-1763) 57
Sévigné, Marie de Rabutin-Chantal (1626-1696) 56
Bachaumont, Louis Petit de (1690-1771) 55
Cicéron (0106-0043 av. J.-C.) 55
Read More
We used two well-curated datasets from the ARTFL Project holdings to form the test samples to identify Enlightenment discourse. The first are the 1,367 documents that comprise the pre-19th century holdings in ARTFL Frantext. This dataset contains a significant, though by no means complete, sample of major and minor French Enlightenment published works. We decide to retain Frantext’s 17th century holdings as part of this study. Thus, the most frequent authors with more than 10 works in this collection are shown in Table One (see bottom of post). The second sample is the complete text of the Encyclopédie of Diderot and d’Alembert as found in the ARTFL edition of this famous work. As mentioned, the ARTFL Frantext corpus and the Encyclopédie are both curated collections that have been largely corrected of input and other errors as well as being reasonable close transcriptions of the original documents with most later editorial interventions having been removed.
The TGB collection, which was meant to be a representative sample of French 19th century print culture, is comprised 128,441 documents which were digitized using Optical Character Recognition. As expected, the quality of the raw data varies widely depending on a whole range of factors, including age, preservation status and print quality, though it was overall of good quality. On the other hand, the document-level metadata was quite inconsistent, and sometimes incorrect, so our collaborators at the Observatoire de la Vie Littéraire had to perform some extensive preliminary work in order to get the data ready for our alignment experiments. This included a number of authorship attribution issues, as well as normalizing the spelling of each author found in the corpus. Additionally, while the vast majority of the texts in the TGB were published during the 19th century, the collection has a significant number of documents which were originally published before 1800. Most of these documents were reprints of earlier texts in complete or selected works or, less commonly, as individual reprints. We used a series of heuristics based on the metadata provided by the BNF to eliminate duplicates and texts originally published before 1800. We removed 17,063 documents from the TGB sample, with the top authors removed listed in Table Two (see bottom of post). This left 112,907 documents in the TGB sample. There are, of course, some titles that should have been retained in the sample and others that should have been removed, since the criteria for removal was based on fairly simple heuristics, such as removing most titles identified as complete works and looking at author year of birth or death, where available, as another criteria. Given that our goal was to draw a picture of the legacy of the Enlightenment using a representative sample of works published in the 19th century, this was a well worth tradeoff given the potential for many false positive reuses that would have been detected from leaving in texts originally written in previous centuries.
Since the primary task of this project is the identification of reused passages, we used the combined word lists of the Frantext sample and the Encyclopédie as the list of words to index in the TGB for both search and alignment applications. This was done in order to reduce the number of unique words (types) to a manageable level and to ignore all the potential OCR errors using the well attested word list of work from our well-curated texts. It did not have an impact on the alignment tasks since we use exact n-gram matching, so any words not found in the source text word list would not be found in the target text. We retained 193,908 types, amounting to a total of 2.1 billion words (tokens).
TextPAIR (Pairwise Alignment of Intertextual Relations)
While the ARTFL Project had built text alignment packages in the past, this system was not built for very large-scale comparisons -- 100,000+ document ranges. As such, we wanted to create a new software package that could retain the strengths of PhiloLine while addressing the problem of scalability. Speed and scalability is important since data-mining projects often make progress through multiple runs testing various parameters and settings. Thus it was necessary for us to build a tool that we could rerun multiple times without having to wait for weeks for results to come in, as had been the case with the original implementation of PhiloLine.
The TextPAIR package was written over the course of many months during which the team at the ARTFL Project was in regular contact with the team at OBVIL in order to gather as much feedback as possible during the development phase. Its algorithm is based on the same principle used in PhiloLine, combining an n-gram representation of text with an alignment logic inspired by research in DNA sequencing. The alignment software comes with a web application designed to facilitate the exploration of the text-reuses found during the detection phase. This application includes both a faceted browser and a time series feature.
Detecting identical or similar passages requires a one-to-one document comparison of every text in the dataset. Our new program, called TextPAIR, generates a list of similar passages (based on a set of flexible matching parameters) shared between any two texts. This simple approach allows us to find borrowings and other instances of text reuse, from quotations to uncited passages and paraphrases, over large heterogeneous corpora. ln order for TextPAIR to find shared passages, we apply a number of transformations to the texts. For instance, we remove all stopwords, common function words, and short words which tend to be ubiquitous and, thus, are not reliable markers of textual similarity. We also reduce the number of orthographic variants by normalizing spelling where possible, and eliminate all words that occur only once in the dataset. The remaining words are then grouped into units of n-number of words – or n-grams – where each unit overlaps with the preceding and following group. These n-grams form a representation of the text that privileges word rareness over ubiquity, unlike textual representations that retain every single word.
Only once we have performed these textual transformations can we start comparing documents to one another. Because it is designed to run on many thousands of texts, TextPAIR’s matching algorithm is relatively simple and straightforward. Any more complex alignment algorithm, such as the Smith-Waterman algorithm, would significantly increase processing time. The basic principle of our text aligner is to compare sequences of n-grams between two documents. Whenever TextPAIR finds matching n-grams, a relatively rare occurrence, it continues comparing until it no longer finds sufficient matching n-grams. It then determines whether the number of contiguous matching n-grams is large enough to constitute a meaningful shared passage.
The TextPAIR package was built using cutting-edge technologies. Installed as a Python package, it includes a text preprocessing component written in Python, a sequence aligner written in Go to maximize speed and scalability, and a single-page web application written with the VueJS framework to guarantee maximum interactivity when text alignments are deployed in the browser. The package is available as open-source on Github, with accompanying documentation meant to assist other research groups in installing and running their own text-reuse experiments.
TextPAIR: General Results and Usage overview
The sequence alignments of the pre 19th century sample of Frantext and the Encyclopédie against the 112,000 documents of the TGB produced a large number of resulting passage pairs, the basic unit of analysis. Figure One shows a typical alignment pair, in this case a passage from the famous Discours Préliminaire reused with some indication of the source in Peignot’s Dictionnaire raisonné de bibliologie. It is important to note that the TextPAIR can detect similar passages with considerable variations which can arise from textual insertions, deletions or modifications along with data capture errors, differences in spellings and word order changes. The figure below uses the “Show differences” feature to highlight the variations between the passage pair.

Each record of the result database stores metadata for each document of the pair from the TEI headers, byte locations and offsets in the corresponding text data files, the passages in question, the size of the alignments, and whether or not the alignment is considered banal. We have in other instances, put addition data describing the passage pair, including whether or not it was from the Bible and related to other passages in the set (commonplace tracking). The databases are loaded into a PostgreSQL relational database with a dedicated interface to allow users to query the document pairs, get summary results and navigate to the original documents at will.
The alignment between the Encyclopédie and the TGB resulted in almost 117,000 records. This number is somewhat deceptive since it contains a number of banal alignments, such as the title of the Encyclopédie and other uninteresting similar passages. Similarly, the alignment between the pre-19th century of ARTFL Frantext and the TGB resulted in just under 295,000 passages, which is reduced to over 201,000 passages when removing short and banal passages. Such filtering is among the many features of the alignment result database implementation. The figure below shows the query form of the Encyclopédie to TGB alignment database, which supports metadata queries to allow the user to focus on specific questions, in this case a search for all aligned passages from articles written by Rousseau.
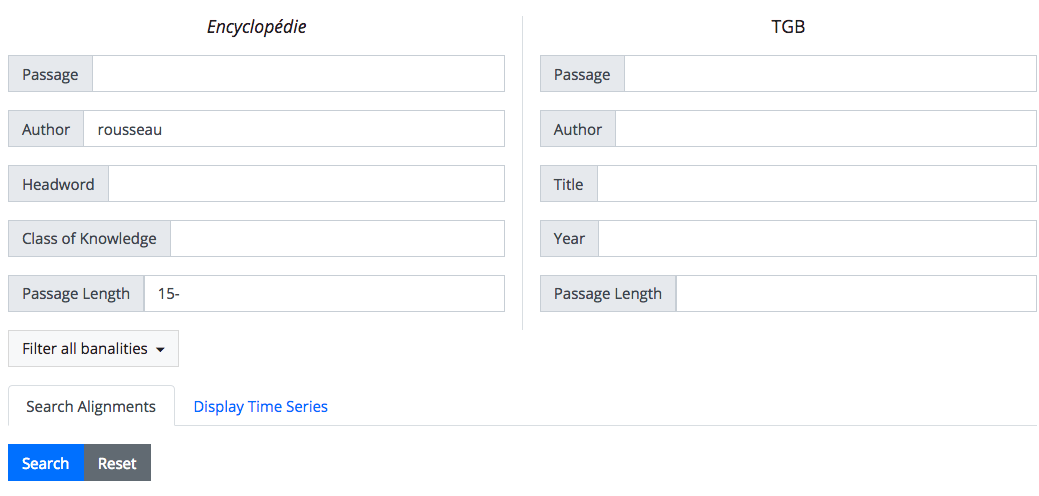
The query returns 611 passages, as shown in the figure below, where the first reused passage in this query is his article Accolade, which is found pretty much verbatim in a dictionary of music from 1825.

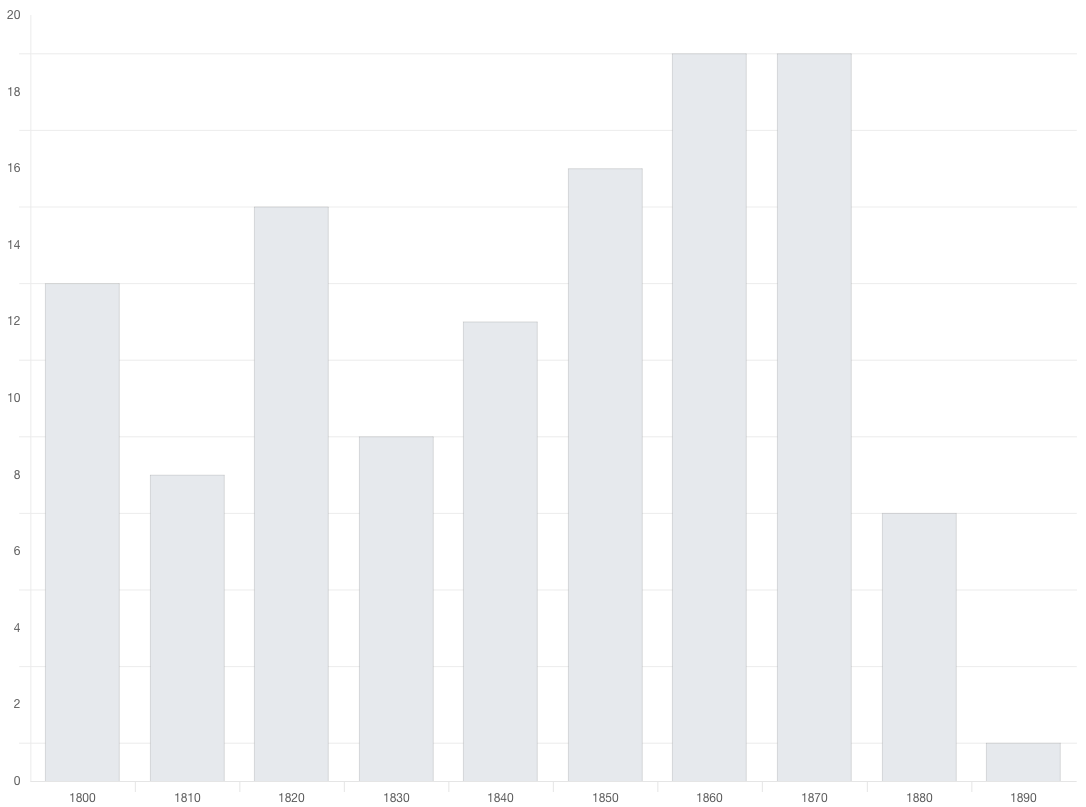
The query interface makes makes extensive use of facets, allowing the user to get frequencies broken down by different criteria. Breaking the reuses of Rousseau’s contributions to the Encyclopédie, it is interesting to note that while most of Rousseau’s entries in the Encyclopédie were about music, it is his political philosophy article “ECONOMIE” that is most reused in the 19th century. The interface supports the generation of time series graphs of the results. Figure Four shows that reuses of the article “ECONOMIE” was fairly consistent through the 19th century.

The Baron d’Holbach is another interesting case. As one of the philosophes with the most notorious reputation as a free-thinking materialists he contributed some of the most controversial articles to the Encyclopédie, such as “Représentants” or “Prêtres”. As shown in the figure on the left, it was his work on chemistry, mineralogy, and German history that is most reused in the 19th century. Instead of his scandalous article on “prêtres” being cited, you get the rather vanilla article “EVEQUE” which outlines the historical background of elector Bishops under the Holy Roman Empire. in fact, not one reuse of d’Holbach’s controversial material was found in the TGB, which sheds new light on our vision of Holbach as not simply an atheist propagandist, but as a man of science whose articles in various domains continued to be cited and used well into the 19th-century. This is an image of d’Holbach that rarely, if ever, occurs in modern intellectual and literary histories.
Algorithms and experiments
We believe that we can begin to use these techniques and these sorts of large-scale databases to refashion literary history, to give a more expansive vision of literary culture, etc.. by identifying various forms of intertextual activity, from reuse to referencing, in a broadened set of 18th-century corpora and to make use of various visualisation tools to navigate the output. In the context of this grant, we decided to concentrate on reuses of the Encyclopédie in the 19th century. While our interpretive work on this set of reuses is still in its initial phases, we have already been able to identify significant findings that change our understanding of the impact of the this great collective work on the 19th century.
We went into this project with the hypothesis that the engin de guerre of the Enlightenment had little to no impact in the 19th century. This was based on the general long-held general opinion on the subject, but it was also backed up by our initial experiments on the ARTFL Frantext corpus of works. However when we moved from this limited corpus to the large-scale TGB corpus, we moved from an exploration of what might be considered as a representative canon of “great works” of the 19th century to what in its vastness might be considered as something coming closer to a representation of a general cultural system.
This change in scale scale led us immediately to note the huge reuse of the Encyclopédie in the genre of dictionaries and encyclopedias published in the nineteenth century. In this area, the Encyclopédie was used as both a model and a source of information. But, more generally, the reuse of the Encyclopédie was more widespread across a broader range of publications than we had expected. So, from this point of view, in spite of the great developments in the sciences in the 19th century, the Encyclopédie remains an important source of information.
While the ARTFL Project had built text alignment packages in the past, this system was not built for very large-scale comparisons -- 100,000+ document ranges. As such, we wanted to create a new software package that could retain the strengths of PhiloLine while addressing the problem of scalability. Speed and scalability is important since data-mining projects often make progress through multiple runs testing various parameters and settings. Thus it was necessary for us to build a tool that we could rerun multiple times without having to wait for weeks for results to come in, as had been the case with the original implementation of PhiloLine.
The TextPAIR package was written over the course of many months during which the team at the ARTFL Project was in regular contact with the team at OBVIL in order to gather as much feedback as possible during the development phase. Its algorithm is based on the same principle used in PhiloLine, combining an n-gram representation of text with an alignment logic inspired by research in DNA sequencing. The alignment software comes with a web application designed to facilitate the exploration of the text-reuses found during the detection phase. This application includes both a faceted browser and a time series feature.
Detecting identical or similar passages requires a one-to-one document comparison of every text in the dataset. Our new program, called TextPAIR, generates a list of similar passages (based on a set of flexible matching parameters) shared between any two texts. This simple approach allows us to find borrowings and other instances of text reuse, from quotations to uncited passages and paraphrases, over large heterogeneous corpora. ln order for TextPAIR to find shared passages, we apply a number of transformations to the texts. For instance, we remove all stopwords, common function words, and short words which tend to be ubiquitous and, thus, are not reliable markers of textual similarity. We also reduce the number of orthographic variants by normalizing spelling where possible, and eliminate all words that occur only once in the dataset. The remaining words are then grouped into units of n-number of words – or n-grams – where each unit overlaps with the preceding and following group. These n-grams form a representation of the text that privileges word rareness over ubiquity, unlike textual representations that retain every single word.
Only once we have performed these textual transformations can we start comparing documents to one another. Because it is designed to run on many thousands of texts, TextPAIR’s matching algorithm is relatively simple and straightforward. Any more complex alignment algorithm, such as the Smith-Waterman algorithm, would significantly increase processing time. The basic principle of our text aligner is to compare sequences of n-grams between two documents. Whenever TextPAIR finds matching n-grams, a relatively rare occurrence, it continues comparing until it no longer finds sufficient matching n-grams. It then determines whether the number of contiguous matching n-grams is large enough to constitute a meaningful shared passage.
The TextPAIR package was built using cutting-edge technologies. Installed as a Python package, it includes a text preprocessing component written in Python, a sequence aligner written in Go to maximize speed and scalability, and a single-page web application written with the VueJS framework to guarantee maximum interactivity when text alignments are deployed in the browser. The package is available as open-source on Github, with accompanying documentation meant to assist other research groups in installing and running their own text-reuse experiments.
TextPAIR: General Results and Usage overview
The sequence alignments of the pre 19th century sample of Frantext and the Encyclopédie against the 112,000 documents of the TGB produced a large number of resulting passage pairs, the basic unit of analysis. Figure One shows a typical alignment pair, in this case a passage from the famous Discours Préliminaire reused with some indication of the source in Peignot’s Dictionnaire raisonné de bibliologie. It is important to note that the TextPAIR can detect similar passages with considerable variations which can arise from textual insertions, deletions or modifications along with data capture errors, differences in spellings and word order changes. The figure below uses the “Show differences” feature to highlight the variations between the passage pair.
The alignment between the Encyclopédie and the TGB resulted in almost 117,000 records. This number is somewhat deceptive since it contains a number of banal alignments, such as the title of the Encyclopédie and other uninteresting similar passages. Similarly, the alignment between the pre-19th century of ARTFL Frantext and the TGB resulted in just under 295,000 passages, which is reduced to over 201,000 passages when removing short and banal passages. Such filtering is among the many features of the alignment result database implementation. The figure below shows the query form of the Encyclopédie to TGB alignment database, which supports metadata queries to allow the user to focus on specific questions, in this case a search for all aligned passages from articles written by Rousseau.
Algorithms and experiments
We believe that we can begin to use these techniques and these sorts of large-scale databases to refashion literary history, to give a more expansive vision of literary culture, etc.. by identifying various forms of intertextual activity, from reuse to referencing, in a broadened set of 18th-century corpora and to make use of various visualisation tools to navigate the output. In the context of this grant, we decided to concentrate on reuses of the Encyclopédie in the 19th century. While our interpretive work on this set of reuses is still in its initial phases, we have already been able to identify significant findings that change our understanding of the impact of the this great collective work on the 19th century.
We went into this project with the hypothesis that the engin de guerre of the Enlightenment had little to no impact in the 19th century. This was based on the general long-held general opinion on the subject, but it was also backed up by our initial experiments on the ARTFL Frantext corpus of works. However when we moved from this limited corpus to the large-scale TGB corpus, we moved from an exploration of what might be considered as a representative canon of “great works” of the 19th century to what in its vastness might be considered as something coming closer to a representation of a general cultural system.
This change in scale scale led us immediately to note the huge reuse of the Encyclopédie in the genre of dictionaries and encyclopedias published in the nineteenth century. In this area, the Encyclopédie was used as both a model and a source of information. But, more generally, the reuse of the Encyclopédie was more widespread across a broader range of publications than we had expected. So, from this point of view, in spite of the great developments in the sciences in the 19th century, the Encyclopédie remains an important source of information.
On the other hand, the articles that are most often cited in today’s discussions of the Encyclopédie, those heavily ideological articles laying out the aims and goals, those that make us see the Encyclopédie as an engin de guerre for the philosophes, are cited less often than we expected. Thus an author like d’Holbach is rarely reprised in the context of his specifically materialistic articles and more for articles he wrote on mineralogy and chemistry. All of this is to say, that Encyclopédie did have a significant impact in the 19th century, but it was not that which we had expected.
This work is just beginning and we will soon begin to look more closely at the bigger picture – not just the Encyclopédie in the TGB, but all of our various 18th century holdings (including the 18th century texts contained in the TGB corpus itself) – to broaden our understanding of reuse of 18th century in the post-Revolutionary era of the 19th century.
Direct Outcomes of this project
This project resulted in a number of related deliverables. Most importantly is the open source distribution of TextPAIR, as this provides a new model for handling very large scale alignment tasks.
https://github.com/ARTFL-Project/text-pair
The importance of this new software is underlined by the ARTFL Project release of a build of the Newberry French Revolution Collection which includes a open release of an alignment database of ARTFL pre-Revolutionary collection and the more than 26,000 Revolutionary documents. This allows scholar to look directly at the long standing question of the relationship between the Enlightenment and the Revolution.
The second and equally important deliverable from this collaborative work is the publication at ARTFL of both alignment databases as described above. These are complete installations of the alignment databases except that we have disabled links to the full texts of underlying datasets owing to agreements with various collaborators.
Home page of our alignment databases: http://artfl-project.uchicago.edu/legacy_eighteenth
ARTFL Encyclopédie to TGB alignment database: https://artflsrv03.uchicago.edu/text-align/encyc_vs_TGB_0803/
The ARTFL-Frantext to TGB alignment database: https://artflsrv03.uchicago.edu/text-align/frantext_vs_TGB_0803/
=====================================
TABLE One: Frequency of authors (shown with dates) in the Frantext Sample
Voltaire, 1694-1778. 85
Diderot, Denis, 1713-1784. 45
Corneille, Pierre, 1606-1684. 37
Molière, 1622-1673. 34
Aulnoy, Madame d'(Marie-Catherine), 1650 or 51-1705. 31
Fontenelle, M. de (Bernard Le Bovier), 1657-1757. 23
Marivaux, Pierre Carlet de Chamblain de, 1688-1763. 22
Bossuet, Jacques Bénigne, 1627-1704. 21
Saint-Simon, Louis de Rouvroy, duc de, 1675-1755 20
Rousseau, Jean-Jacques, 1712-1778. 17
Mersenne, Marin, 1588-1648. 16
Charrière, Isabelle de, 1740-1805. 14
Fénelon, François de Salignac de La Mothe-, 1651-1715. 13
Montesquieu, Charles de Secondat, baron de, 1689-1755. 13
Prévost, abbé, 1697-1763. 13
Racine, Jean, 1639-1699. 13
La Fontaine, Jean de, 1621-1695. 11
Marot, Clément 11
Balzac, Jean-Louis Guez, seigneur de, 1597-1654. 10
Du Bellay, Joachim 10
Scudéry, M. de (Georges), 1601-1667. 10
Table Two: Top Authors removed from TGB
Voltaire (1694-1778) 249
Molière (1622-1673) 243
Racine, Jean (1639-1699) 139
Corneille, Pierre (1606-1684) 132
La Fontaine, Jean de (1621-1695) 129
Chateaubriand, François-René de (1768-1848) 112
Scott, Walter (1771-1832) 105
Boileau, Nicolas (1636-1711) 100
Fénelon, François de (1651-1715) 96
Scribe, Eugène (1791-1861) 84
Rousseau, Jean-Jacques (1712-1778) 72
Rollin, Charles (1661-1741) 69
Diderot, Denis (1713-1784) 64
Louis (1755-1824) 63
Florian, Jean-Pierre Claris de (1755-1794) 60
Marmontel, Jean-François (1723-1799) 58
Prévost, Antoine François (1697-1763) 57
Sévigné, Marie de Rabutin-Chantal (1626-1696) 56
Bachaumont, Louis Petit de (1690-1771) 55
Cicéron (0106-0043 av. J.-C.) 55



