Over three decades ago, while working with the splendid French Revolution Collection (FRC) at the Newberry Library in Chicago, I came across one of those entertaining little finds that stick in your memory and makes working in great research library so worthwhile. Came across is not quite right, since the librarians at the Newberry had begun working on a database catalog of the collection, starting with the anonymous texts from the FRC. Searching for "Club" in this early database, which I recall was running on a stand-alone IBM-PC/AT from that epoch, generated a list of titles which included a document which I probably would not have found using standard printed catalogues such as Tourneux's Bibliographie... . The Dénonciation a toutes les puissances de l'Europe : d'un plan de conjuration contre sa tranquilité général (link), is a right wing attack on the Société de 1789, a political club founded by Condorcet and Sieyès in 1790[1].
What stuck in my mind for all these many years is the basis of the attack; that the "Club de la Propagande" was part of an American plan to destabilize the thrones of Europe with the ultimate objective of subjugating the old world to the new:
Elle qu'une légère vapeur qui s'élève du sein de la mer, comme le vestige d'un homme, attire du plus loin tous les nuages étendus dans l'air, se condense, s'obscurcit, & éclate enfin en une furieuse tempête ; tel on a vu le spectre pâle & maigre de l’insurrection, sortant d'une terre ingrate, & du milieu d'enfans rebelles parricides, croître & s'élever en un colonne fastueux, qui, posant un de ses pieds sur l'hémisphere qui l'enfanta, essaya de l'autre de franchir l'Océan, pour porter ses ravages sur celui-ci; & comme si l’Amérique avoir encore plus à se plaindre qu'à se louer de l'Europe, elle a envoyé l'anarchie à celle-ci, pour prix du soin qu’elle a pais de la civiliser.
C'est elle qui est le berceau des convulsions qui commencent à agiter notre continent; c'est-là qu'est né le projet de soumettre l'ancien au nouveau monde ... (link)
C'est elle qui est le berceau des convulsions qui commencent à agiter notre continent; c'est-là qu'est né le projet de soumettre l'ancien au nouveau monde ... (link)
Like all good political invective, there were some grains of truth to the attack. The Société was no doubt rather pro-American in its orientation naming, for example, Franklin, mentioned by name in the Dénonciation, as an honorary member. The anonymous author identifies the root cause of all of the disorders in France and Europe are due to the contagion liberal ideas.
Les monstres! Ils ont égaré le peuple par deux mots l’ont toujours rendu la dupe des fourbes = égalité, & désobéissance = l’un, ils le lui on présenté comme un droit naturel. L’autre, comme, un moyen légitime d’y rentrer. = II ne connoit pas, ce malheureux peuple, le pouvoir magique de ces deux mots, qui ont couvert la terre de crimes & de sang, qui ont rendu son séjour un objet d’horreur pour la vertu[?], & qui lui font, à la fin, désirer à lui-même un remede qu’il abhorre.
To insure that his readers were precisely able to identify the source of the conspiracy, the author attached a 10 page extract from Sieyès' Ébauche d'un nouveau plan de société patriotique, adopté par le Club de mil sept cent quatre-vingt-neuf (BNF) which includes a discussion of l'art social as well as elements of the club's formal organization.
The good folks at the Newberry produced a photocopy of this little treasure shortly after, which I squirreled away in my files and have kept, along with the charge slips and other notes, to this day. Yes, I should provide seriously consider cleaning out the old paper files at one point.
I had occasion to revisit this text several years ago, almost three decades after my first reading, in a completely different context. In 2016-7, the Newberry Library made the entire collection available in digital format. The release on Github consists of Library’s exceptional metadata describing each object, the OCR text data, and links to the digital facsimiles accessible from the Internet Archive, encouraging researchers and instructors to incorporate the digital collection in new kinds of scholarship and engagement. In 2018, the ARTFL Project, in collaboration with the Newberry, released two versions of the collection under PhiloLogic4 (link). The collection has also been extremely valuable as a corpus to test various new applications based on sequence alignment and machine learning. In this course of this work, I was pleased to find the Dénonciation was indeed included in this collection.

Part of our experimental work in developing the Intertextual Hub, is the deployment of various text mining and machine learning algorithms to a number of large heterogeneous collections. As I was preparing a presentation on some of this work, I looked up the Dénonciation once more, to observe that the first topic listed in the citation is topic 34, the top words of which are: "election electeur nomination assemblee scrutin majorite elu choix membre votant" (accents removed). Closer examination of the topic model for this document reveals pretty much the kinds of subjects that I had recalled:

With the notable exception of the first topic, number 34. This unexpected topic sent me back to the text itself for the first time in decades, reminding me that significant parts of the Dénonciation contains an almost comically complex description of the election process of members taken from Sieyès' Ébauche... . Here is just part of the involved process to elect members, the number of whom would be limited to 660:
Il est d'une bonne vue de donner au plus grand nombre possible des membres, la facilité de prendre part aux scrutins, afin qu'ils soient d'autant mieux le résultat de la volonté générale ; en conséquence on pourroit régler, que chaque scrutin se fera en quatre parties ; savoir, au premier & au deuxieme jours , & au quinze & au seize de chaque mois; de maniéré que le scrutin commence le matin du premier du mois ; par exemple , depuis onze heures jusqu'à midi , le soir pour ceux qui n'auroient pas pu se présenter le matin; le même scrutin continueroit le lendemain matin, ne se terminera que le, soir. Alors seulement on feroit le recensement. Pour prévenir les abus , il suffiroit que les feuilles de papier , remises aux membres fussent signées par un commissaire , qu'en recevant sa feuille , chaque membre s'inscrivit , ou fut inscrit par un commissaire; on connaîtroit par-là le nombre des feuilles données , ceux qui ont reçu la leur. Il faudrait encore que la boëte du scrutin fut fermée à clef, & qu’on ne pût en rien tirer jusqu’au moment du recensement. (emphasis mine)
Trying to determine the "general will" just might well require such care and management of election procedures, but I have to admit that I wondered if I had missed the joke the first time around. Was this a spoof of Condorcet's electoral combinatorics?

Alas, you can't make this stuff up. Or at least the author of the
Dénonciation did not have to. The current version of the Intertextual Hub is based on a number of collections and the system provides two links to the original text by Sieyès. The Topic Model representation of the Dénonciation in the Hub
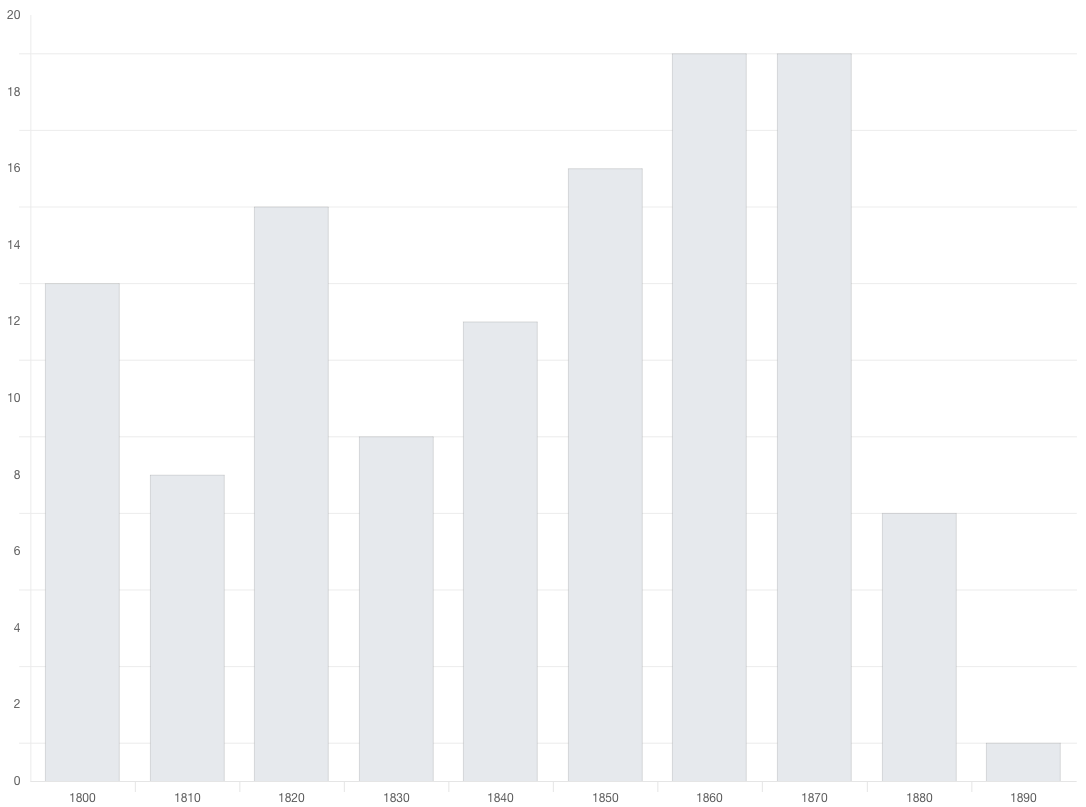
shows 2 parts of the Ebauche as being the top 2 most similar documents by a measure of vocabulary.


The system allows the reader to compare two passages side by side to examine just how closely related they are.

It is important to note that Sieyès' Ébauche is not part of the Newberry French Revolution collection, but is contained in the Goldsmiths-Kress collection of French works related to political economy. The different techniques employed in our implementation of the Intertextual Hub, lexical density and sequence alignment, gave two different avenues to indicate the the two documents are related. Being contained in different collections is important in itself. The Dénonciation does not have internal divisions (chapters or sections) while the Ébauche does. Thus similar documents function from Dénonciation the does not find the Ébauche, because it is treated as parts of a document. To find various potential points of contact between documents, we use various measures which are complementary and necessary, since we are trying to find relationships between items that are not all the same. Thus, some of the complexity of the Hub is an artifact of treating huge numbers of heterogeneous documents.
My long, very intermittent, relationship with Dénonciation a toutes les puissances de l'Europe..., a minor text if ever there was one, is illustrative of the progress I believe we have seen over the last three decades in digital humanities. I first found it as part of an experimental bibliographic database in the late 1980s and able to access it only in person and store it as a photocopy. Decades later, it became a small part of an extraordinary collection, searchable as both excellent metadata and uncorrected OCR text. Our current work reflected in the Intertextual Hub, is to build and environment which can draw connections between documents across collections, using the power of distant reading tools to help navigate and elucidate closer considerations of even minor texts.
References
1 Mark Olsen, "A Failure of Enlightened Politics in the French Revolution: the Société de 1789" in French History 6 (1992): 303-34. (DOI)
1 Mark Olsen, "A Failure of Enlightened Politics in the French Revolution: the Société de 1789" in French History 6 (1992): 303-34. (DOI)